Not One Brain, But Many: How Mixture of Experts (MoE) Makes AI Smarter and Faster
As AI models have grown more powerful, they've also become colossal in size. Training and running these massive "monolithic" models requires staggering amounts of computer power, making them incredibly expensive and slow. But a brilliant architectural design called Mixture of Experts (MoE) is changing the game.
Instead of one giant, generalist brain trying to know everything, an MoE model is like a committee of specialized experts. When a question comes in, the model smartly routes it to only the experts best suited to handle the task.
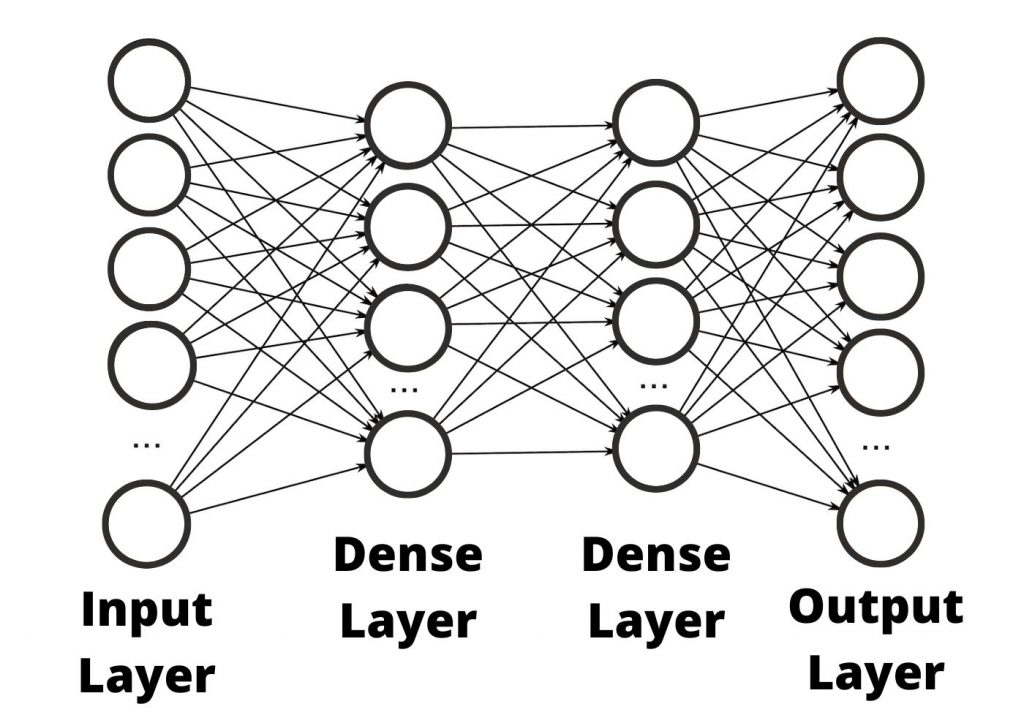
The Old Way: The Dense, Monolithic Model
Traditionally, Large Language Models have been "dense." This means that every time you ask the model a question—no matter how simple—the entire neural network, with its hundreds of billions of connections, has to fire up and process the information.
Think of it like a single, all-knowing professor who has mastered every subject. If you ask them "What is 2+2?", they have to engage their entire brain—the parts that know quantum physics, Shakespearean literature, and ancient history—just to give you the simple answer. It's incredibly powerful, but also incredibly inefficient.
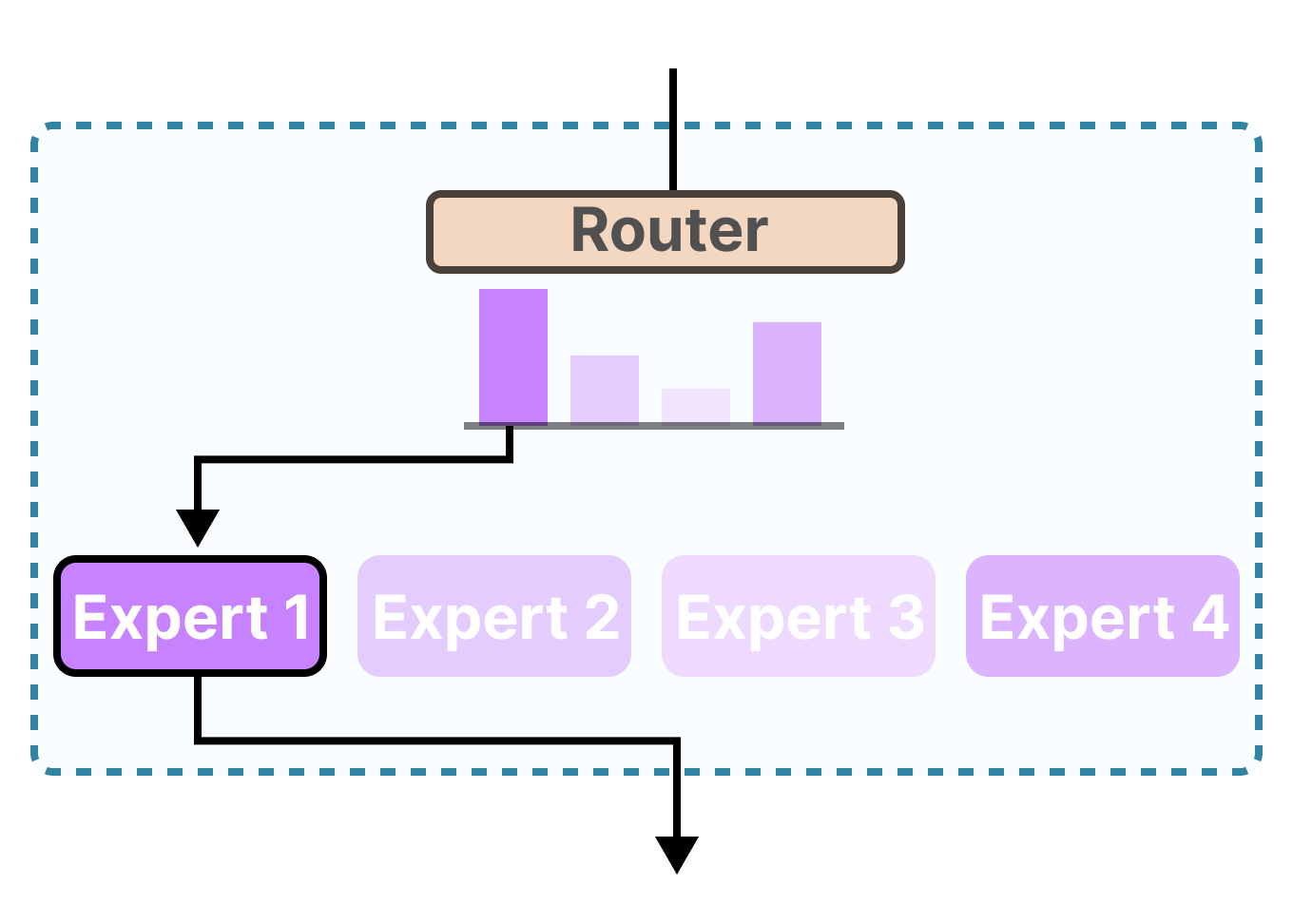
The New Way: The Mixture of Experts (MoE) Committee
An MoE model takes a "divide and conquer" approach. It's composed of two key parts:
- The Experts: Instead of one giant network, the model is broken up into many smaller, specialized neural networks called "experts." Each expert might develop a knack for a particular topic, like creative writing, coding, historical analysis, or logical reasoning.
- The Router: This is a small, efficient neural network that acts as a project manager or a receptionist. Its only job is to look at an incoming query and quickly decide which one or two experts from the committee are the best fit for the job.
How it Works:
When you ask an MoE model a question like, "Write a Python script to analyze historical stock data," the following happens:
- The Router instantly analyzes the prompt.
- It determines that this task requires knowledge of both programming and financial history.
- It activates only the "Python Coding Expert" and the "Financial History Expert."
- The other experts—like the "Poetry Expert" or the "Biology Expert"—remain dormant, saving energy.
- The selected experts work together on the problem and generate the final answer.
The Game-Changing Advantages of MoE
This clever design has profound benefits that are pushing the entire field of AI forward:
- Incredible Efficiency: Since only a small fraction of the model is used for any given query, MoE models are much faster and cheaper to run than dense models of a similar size. This is their biggest advantage.
- Massive Scalability: Researchers can build models with a truly vast amount of total knowledge (by adding more experts) without the model becoming proportionally slower. You can have a model with a trillion "parameters" (the connections that store knowledge), but it might only use 200 billion for any one task, making it feel much faster.
- Better Specialization: By allowing experts to specialize, the model can develop deeper knowledge in specific domains, potentially leading to higher-quality outputs for complex, multi-faceted questions.
Models like Mistral's Mixtral 8x7B and Grok from xAI are built on this architecture. They are paving the way for a future where AI can be both incredibly knowledgeable and remarkably fast, bringing us one step closer to truly powerful and accessible artificial intelligence.