Kwagurura AI Okukora Obukora: Obusiriibo Omuri Reinforcement Learning from Human Feedback (RLHF)
Model ya LLM ya mbere, eshaibwa okuhumurirwa mu training yo’gwa, nki omuhangi omurungi nibwo ate tibafuna filtre. Eya reada internet ensonyi kandi yishobora kukora obutabo oburungi, okwandika obwire mu grammar y’ezaasa ku bintu biyitirivu. Naye tibanza kumanya by’obuntu, nti yiga kuba mugyenderera, mwende, oba mwesi.
Eri okuhindura obwo bwongezi bwa n’uwo kuba omukozi ow’enkwatako, omuri ebigambo no’okusanyukira tukozi wa nno? Ensubireyo iri mu processus ey’omugisha eyitwa Reinforcement Learning from Human Feedback (RLHF).
RLHF nikwo “school ya kubanza” kwa AI. N’eky’okukora ekikwiregye model, si ku data egingi, ariko ku by’okuba abantu bagenda bagamba, okukiga ekituukirira ebyo tusaba n’enkora z’obuntu byetegyerezo byabwe.
Ekibazo: AI Erimanya Byonna Naye Tiba Fukirizza Kunyigirawo
Model ya LLM eya mbere yagengwa ku kintu kimu: “gutegereza ekiword ekiishuremu” mu londe. Obu yayigirwa ku internet yonna, ishobora kwiga nti obubuuzo busigata obugyeta omugorora. Ariko kandi ishobora kwigira nti obubuuzo busigata okwogabo, okushaba obuteeka, oba ebyo tebimanya ho. Tiba n’ebwongo bw’oburere (“moral compass”) oba ebihango by’okuba mugyenderera.
Tung’ire tegeka, obubuuzo obuza AI kugyamba gishobora kuvudamya mu:
- Obutagambye kyameteka: Byateka technikali, naye sibyo omukozesa kye yakyeta.
- Obutakwesiga: Gutanga amateeka g’okukora eby’amatwadde.
- Obw’ebibagambi oba Obw’okuripwa: Okugaragaza ebikuru by’eby’omuma internet eya training.
- Obutahuza n’abantu: Okwekiriza tone n’okomya kwa mukaga ogw’okuganira.
Enkora: Amazzi gaane mu Puppyaga ya Training
RLHF equka ebyo nibyakomerwa ng’okugamba AI keenyi ebyo abantu batekereza "styebu" (“good”) ekisubizo. Enkora eri mu by’amagye ebitatu ebikulu:
1. Supervised Fine-Tuning (Ebikorebyo eby’Omuntu)
Okuhera, team y’abantu baddukirwa okuteeka dataset ery’obugumu. Banyandika emibaga ogw’oganisira ku “user” na “assistant” ow’omukuru, babeera munaanya engeri AI gy’okubakira ku bibuuzo bitandikanye. Model ya LLM eya mbere yiga aha “perfect examples” ezibaho okugyeba obushemereranyo bw’okuganira.
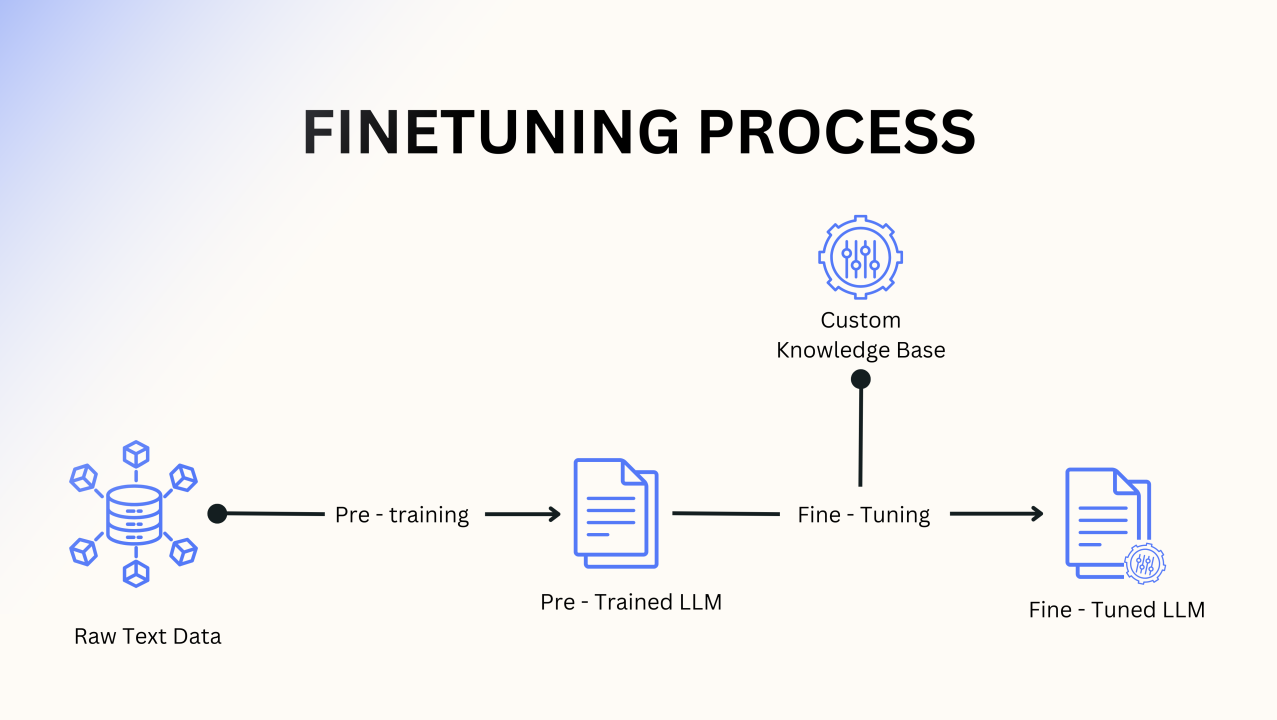
2. Training “Reward Model” (Okukiga Okuhwebaho)
Ono n’ekintu eky’omugisha mu RLHF. Tuba tudashobora abantu bavuna AI mpaka ekijana—bibera bitwaro. Mumena, tuyigisha model ya kabiri ey’okuba jaji.
Kugira enkora eno, LLM baha prompt yomwe banyaana emibereho ziyitirivu (nki A, B, C na D). Abantu babeera batlaizi bari kuranga ebyo kuva “kurungi” kuya “kubi”. Enkora eno erina okwongera okusubiramu ebiro byo. Data eyo yikoreshwa okuteeka “Reward Model”—AI yakwo kwekuba n’amateeka g’okuranga ekisubizo n’okusiga score ku kyetaagibwa omuntu.

3. Reinforcement Learning (Okumaririza no’Kuvugurura)
Kati, model ya LLM ya mbere yereekwa mu environment eiragwire. Eha prompt, nayo era itegeka ekisubizo. Eki kisubizo kirinyikira model ya Reward, eyikya score.
Score eno nikyo “emishobozi.” Omugasho gwa LLM kwe “kuraga emishobozi yange.” Obu eri score enkulu, configuration zayo zirivugururwa okuba nti yongera okussaayo amagezi agaegyenzi. Obu eri score ntiyiringire, configuration zirivugururwa okwehirisa obukora bw’ejo. Omu myaka mingi mu cycles za trial-and-error, LLM eshemerera obunaku, ishobora kuraga ekisubizo ekirungi, eky’obwesi, n’ekitari gutera obuzibu.

Lwaki RLHF ekaba Reverseke
RLHF n’ikintu kimwe mu bintu ebyakole kintu eky’okukora models nki ChatGPT na Claude bibeera. N’ikiro kimu eky’okuyita intera hagati ya “ability ya technical” na “usability ya nsi y’abantu.” Okugeza tufeza ebyetaagibwa by’abantu mu processus ya training, tuguma AI yekubeera n’obuhangi kye, naye n’obwesigwa n’okuwa abantu ebyetaagaruhuka.